A benchmark to testify the performance of
personalized news headline generation approaches
Overall Description
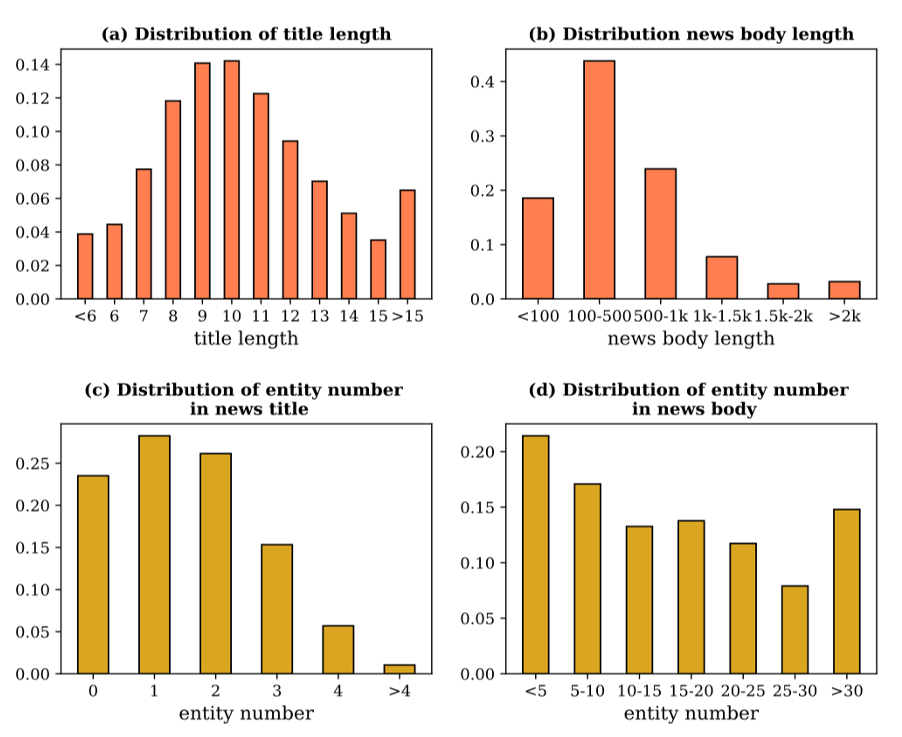
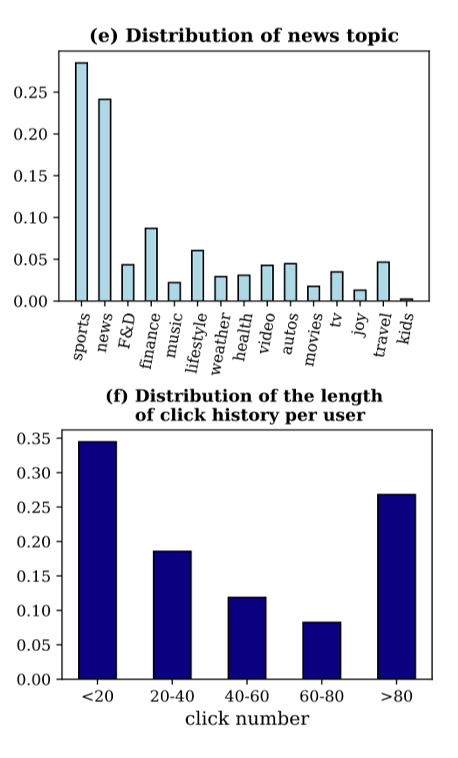
The PENS dataset contains 113,762 pieces of News whose topics are distributed into 15 categories. Each news includes a news ID, a title, a body and a category manually tagged by editors. The average length of news title and news body is 10.5 and 549.0, individually. Entities from each news title are extracted and then linked to those in WikiData.
We sample 500, 000 user-news impressions from June 13, 2019, to July 3, 2019, as the training set. An impression log records the news articles displayed to a user as well as the click behaviors on these news articles when he/she visits the news website at a specific time. The format of each labeled sample in our training set is [uID, tmp, clkNews, uclkNews, clkedHis], where uID indicates the anonymous ID of a user, tmp denotes the timestamp of this impression record. clkNews and uclkNews are the clicked news and un-clicked news in this impression, respectively. clkedHis represents the news articles previously clicked by this user. All the samples in clkNews, uclkNews and clkedHis are sorted by the user’s click time.
Dataset Format
Our provided training dataset has contains the following files:
| File Name | Description |
|---|---|
| news.tsv | The information of news articles |
| train.tsv | The click histories and impression logs of users for training |
| valid.tsv | The click histories and impression logs of users for validation |
news.tsv contains the detailed information of news articles involved in the train.tsv and valid.tsv files. It has 7 columns divided by the tab symbol:
| Column | Example Context | Description |
|---|---|---|
| News ID | N10000 | Unique ID of news |
| Category | sports | Belong to one of 15 categories |
| Topic | soccer | Specific topic of news |
| Headline | Predicting Atlanta United's lineup against Columbus Crew in the U.S. Open Cup | |
| News body | Only FIVE internationals allowed, count em, FIVE! So first off we should say, per our usual Atlanta United lineup predictions, this will be wrong... | |
| Title entity | {"Atlanta United's": 'Atlanta United FC'} | The mapping between the phrase in title and the entity in wikidata |
| Entity content | {'Atlanta United FC': {
'type': 'item', 'id': 'Q16836317', 'labels': {'en': {'language': 'en', 'value': 'Atlanta United FC'}, ...}, 'descriptions': {'en': {'language': 'en', 'value': 'Football team in the city of Atlanta, Georgia, United States'}, ...}, 'aliases': {'en': [{'language': 'en', 'value': 'Atlanta United'}, {'language': 'en', 'value': 'ATL UTD'}, {'language': 'en', 'value': 'ATL UTD FC'}, ...], ...}, 'claims': {'P31': [{'mainsnak': {'snaktype': 'value', 'property': 'P31', 'datavalue': {'value' {'entity-type': 'item', 'numeric-id': 476028, 'id': 'Q476028'}, 'type': 'wikibase-entityid'}, 'datatype': 'wikibase-item'}, 'type': 'statement', 'id': 'Q16836317$2462E96F-B25E-4BE9-9CAC-876FF99CD5DA', 'rank': 'normal'}, ... ], ...}, 'sitelinks': {'zhwiki': {'site': 'zhwiki', 'title': '阿特蘭大聯足球會', 'badges': []}, ...} 'lastrevid': 1452771827}, ...} | The mapping between the entity name and the entity content in wikidata. For detailed data structure, please refer to the official documents. |
train.tsv & valid.tsv contains the impression logs and users' news click histories. They have 9 columns divided by the tab symbol:
| Column | Example Context | Description |
|---|---|---|
| UserID | U335175 | Unique ID of users |
| ClicknewsID | N41340 N27570 N83288 ... | The user’s historical clicked news |
| dwelltime | 116 23 59 ... | The duration of browsing historical clicked news |
| exposure_time | 6/19/2019 5:10:01 AM#TAB#... | The exposure time of historical clicked news and can be split by '#TAB#' |
| pos | N55476 N103556 N52756 ... | The clicked news in this impression |
| neg | N48119 N92507 N92467 ... | The unclicked news in this impression |
| start | 7/3/2019 6:43:49 AM | Start time of this impression |
| end | 7/3/2019 7:06:06 AM | End time of this impression |
| dwelltime_pos | 34 83 79 ... | The duration of browsing clicked news in this impression |
Overall Description
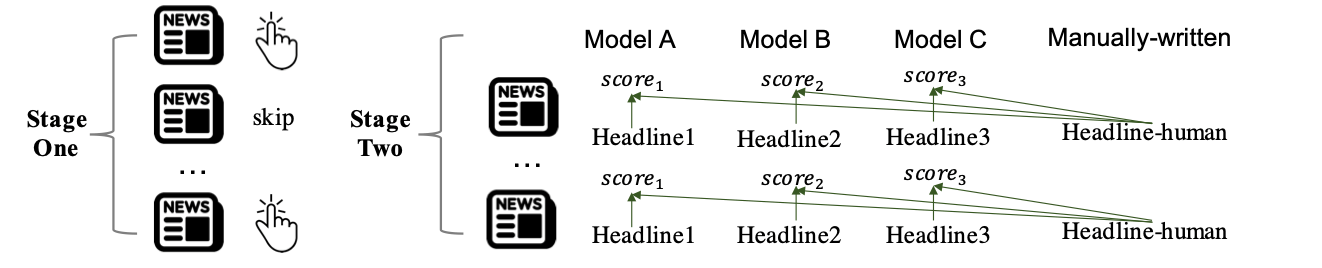
The construction process of test set: To provide an offline testbed, we invited 103 English native speakers (all are college students) to manually create a test set by two stages.
At the first stage, each person browses 1,000 news headlines and marks at least 50 pieces he/she is interested in. These exhibited news were randomly selected from our news corpus and were arranged by their first exposure time.
At the second stage, everyone is asked to write down their preferred headlines for another 200 unseen news articles from our dataset without exhibiting them the original news titles, while highlighting some important segments in the original news articles as well. These unseen news articles are evenly sampled, and we redundantly assign them to make sure each news is exhibited to four people on average. The quality of these manually-written headlines were checked by professional editors from the perspective of the factual aspect of media frame. Low-quality headlines, e.g. containing wrong factual information, inconsistent with the news body, too-short or overlong, etc., are excluded. The rest are regarded as the personalized reading focuses of these annotators on the articles, and are taken as gold-standard headlines in our dataset.
Dataset Format
Our provided test dataset has the following contexts:
| Column | Example Context | Description |
|---|---|---|
| userid | NT1 | The unique ID of 103 users |
| clicknewsID | N108480,N38238,N35068, ... | The user’s historical clicked news collected at the first stage |
| posnewID | N24110,N62769,N36186, ... | The exhibited news for each user at the second stage |
| rewrite_titles | 'Legal battle looms over Trump EPA\'s rule change of Obama\'s Clean Power Plan rule ... | The manually-written news headlines for the exhibited news articles and can be split by '#TAB#' |
The web page was started with Mobirise